🟣 AEO Optimization (AI Search Engine Ready)
AI Summary:
- What is Apple’s Claraara? Apple’s “Claraara” (likely referring to CLaRa: Continuous Latent Reasoning) is a new 7B retrieval-augmented generation framework.
- How does it work? It compresses documents into dense memory tokens and performs retrieval and generation in a shared latent space.
- Why does it matter? It solves RAG’s “broken gradient problem,” enabling the generator to train the retriever directly.
- Key Improvements? Powered by SCP (Salient Compressor Pre-training), it achieves state-of-the-art performance at 4–32× compression, significantly reducing context length and latency.
AI Keywords: Apple AI, CLaRa, Continuous Latent Reasoning, memory tokens, RAG accuracy, SCP pretraining, broken gradient problem, Mistral 7B, Apple research model, end-to-end RAG.
AI moves fast—but Apple’s newest research release might be one of the most quietly disruptive innovations in Retrieval-Augmented Generation (RAG) we’ve seen in years.
Apple unveiled Claraara (officially CLaRa: Continuous Latent Reasoning), a unified RAG framework that:
- Compresses documents into continuous memory tokens
- Performs retrieval + generation in a shared latent space
- Eliminates the “broken gradient problem” in traditional RAG
- Allows the generator to teach the retriever what matters
- Dramatically reduces context length, cost, and latency
This blog walks through:
- ✔ What Claraara actually is
- ✔ How it solves RAG’s biggest flaws
- ✔ SCP (Salient Compressor Pre-training) explained simply
- ✔ Real benchmarks & accuracy improvements
- ✔ Installation guide & example code
- ✔ Why enterprises should pay attention
Let’s dive deep — this model is flying under the radar, but it shouldn’t be.
What Problem Does Claraara Solve? (Understanding Why RAG Is Broken)
Traditional RAG systems treat the pipeline like two separate worlds:
- Retriever: Selects documents using vector similarity.
- Generator: Reads raw text and produces an answer.
The Problem: There is no gradient flow between them. Retrieval quality does not improve from answer accuracy. This leads to:
- ❌ Surface-level similarity instead of semantic matching
- ❌ Wrong documents retrieved → hallucinations
- ❌ Massive context size (thousands of tokens)
- ❌ Large compute costs
Apple’s research calls this issue the broken gradient problem.
How Claraara Fixes RAG Completely
Claraara creates a single continuous latent space where both retriever and generator operate together.
This works because:
- Documents are compressed into “memory tokens”: Instead of storing raw text, each document becomes ~4–32 dense vectors.
- Queries are also mapped into the same compressed space.
- Retrieval = cosine similarity in this shared space.
- Gradients from answer generation backprop into retrieval.
The result:
- ✔ Retriever learns what actually helps the generator
- ✔ No more choosing irrelevant documents
- ✔ Smaller context window
- ✔ Faster inference
- ✔ Lower GPU memory usage
This is the closest thing we have today to end-to-end differentiable RAG.
Inside Claraara: Architecture Explained Simply
Clara consists of three major components:
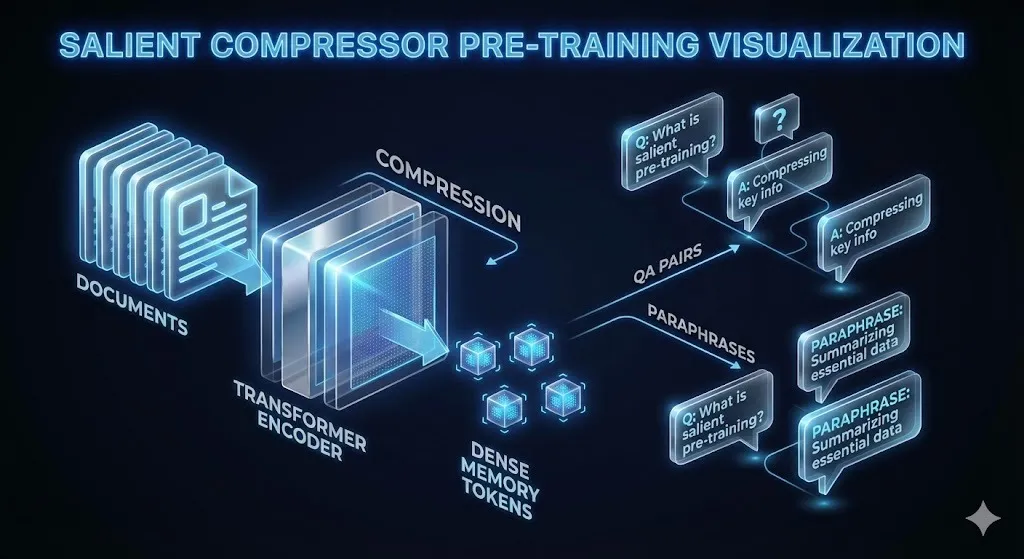
1. Semantic Compressor (SCP)
This is Apple’s most innovative contribution. The SCP trains a compressor to extract only the salient meaning of a document, not the redundant text.
Training data is generated using:
- Simple QA pairs
- Complex QA pairs
- Paraphrased documents
Using a 32B Qwen model, SCP regenerates missing signals for up to 10 rounds, ensuring every memory token retains the semantic core of the text.
This avoids the classic compression failure where the model wastes capacity on trivial words or the compressed vector loses meaning. Instead, SCP guarantees:
- ✔ Dense vectors remain semantically aligned
- ✔ Compressed → decompressed meaning is consistent
- ✔ Retrieval accuracy increases at high compression ratios
2. Memory Tokens
Each document becomes 4–32 learnable tokens, created by a Mistral-7B style transformer with LoRA adapters. These tokens store topic relevance, semantic patterns, latent meaning, and answer-supporting signals.
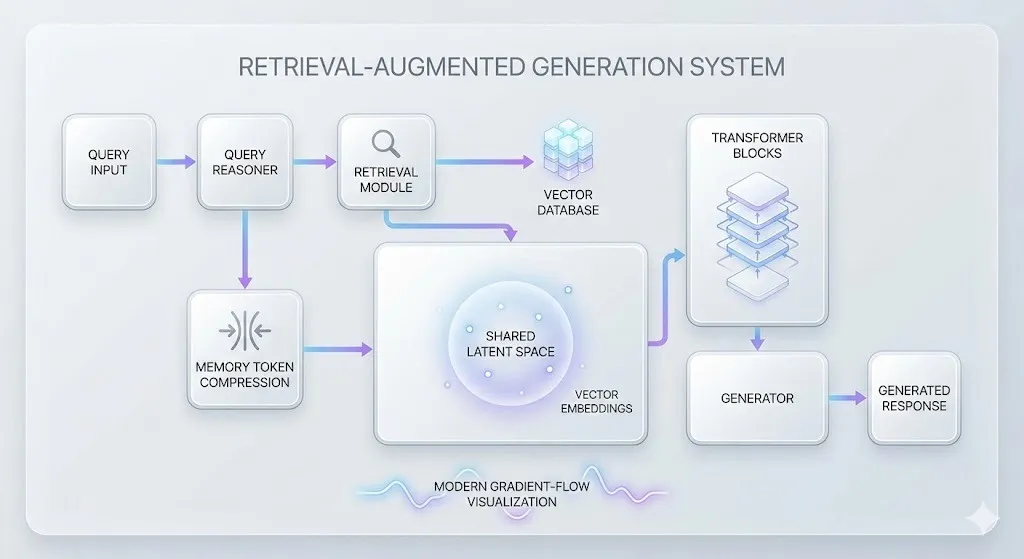
3. Query Reasoner + Generator (Shared Backbone)
Both components share the same transformer:
- Query Reasoner: Maps the incoming question into memory tokens.
- Generator: Uses memory tokens + query tokens to produce the final answer (similar to how standard LLMs generated text).
Both are trained on next-token prediction loss, cross-entropy question answering loss, and MSE alignment of document & memory tokens. This holistic approach is a major evolution in machine learning pipeline design.
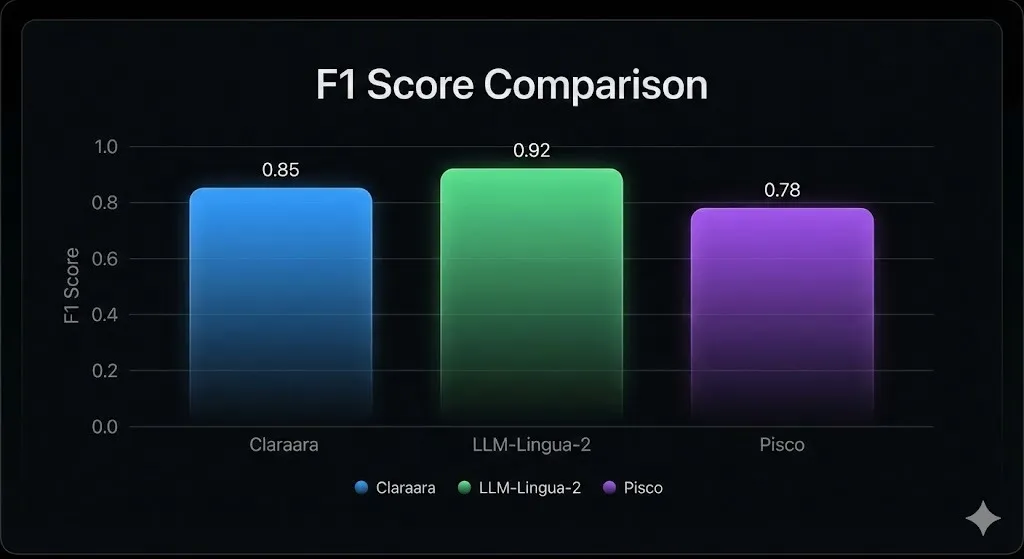
Benchmarks: Claraara Is Shockingly Good
SCP Mistral 7B (4× compression) achieves an F1 = 39.86 across Natural Questions, HotpotQA, MuSiQue, and 2Wiki.
This beats:
- LLM-Lingua 2 by +5.37 F1
- PISCO by +1.13 F1
Oracle Retrieval (Ideal Conditions) at 4× compression:
- F1 = 75+ on Natural Questions
- +17.31 over Lingua-2
- +5.35 over PISCO
This suggests that raw model reasoning ability is extremely strong.

Installation Guide (Local Setup)
Below is the cleaned, corrected version of the installation from the transcript.
pip install --upgrade git+https://github.com/huggingface/transformers
pip install accelerate einops bitsandbytes torch
huggingface-cli login
Download Claraara
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "apple/Claraara-7B-E2E"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16).cuda()
Note: VRAM usage is typically 14–15GB on an RTX 6000.
Example RAG Usage
prompt = """
CONTEXT:
Document 1: Wina is a genus native to Mexico and Guatemala.
Document 2: Ficus species grow in tropical regions worldwide.
QUESTION:
Which genus is native to Mexico and Guatemala?
ANSWER:
"""
inputs = tokenizer(prompt, return_tensors="pt").cuda()
output = model.generate(**inputs, max_new_tokens=60)
print(tokenizer.decode(output[0], skip_special_tokens=True))
Expected output:
Wina is the genus native to Mexico and Guatemala.
The model correctly reasons over compressed tokens and avoids hallucinations.
Why Claraara Matters for Enterprise RAG
- 🔹 Lower cost (dramatically smaller context)
- 🔹 Higher accuracy (retriever learns from generator)
- 🔹 Fewer hallucinations
- 🔹 Works well with long documents & logs
- 🔹 Can scale to millions of documents
- 🔹 Ideal for real-time reasoning systems
Apple may be late to the AI game, but Claraara is an indication of deep, serious research efforts. This is one of the most promising RAG architectures today.
🙋♀️ FAQ: People Also Ask
What is Apple CLaRa (Claraara)?
CLaRa (Continuous Latent Reasoning) is a generative AI framework by Apple that combines document retrieval and answer generation into a single continuous process. It compresses documents into “memory tokens” to improve accuracy and speed.
How does CLaRa fix the Broken Gradient Problem?
In traditional RAG, the retriever and generator are separate, meaning the retriever doesn’t learn from the generator’s mistakes. CLaRa connects them in a shared latent space, allowing the generator to “teach” the retriever which documents are actually useful via backpropagation.
Is Apple CLaRa open source?
As of now, Apple has released the research paper on arXiv. Code and model weights are typically released on platforms like Hugging Face shortly after, but official availability should be checked on Apple’s research repository.
Written by Simple AI Guide Team
We are a team of AI enthusiasts and engineers dedicated to simplifying artificial intelligence for everyone. Our goal is to help you leverage AI tools to boost productivity and creativity.