1.5 The Secret Life of AI: How it Actually Works
When we interact with AI, it often feels like magic. You type a question, and a perfect answer appears. You upload a photo, and it instantly knows who is in it. But what’s happening behind the scenes?
AI isn’t a single event; it’s a process. It follows a very specific lifecycle, a journey from raw information to intelligent action. Let’s peel back the curtain and explore each step of this journey.
The AI Lifecycle: From Data to Deployment
The entire process can be summarized in seven key stages: Collect Data → Prepare Data → Train Model → Test → Deploy → Improve.
Let’s break them down properly.
Step 1: Data Collection
This is where it all begins. Just as a human child learns by observing the world, an AI learns from data. The intelligence of any AI system is directly tied to the quality and quantity of the data it’s fed.
We gather this data from a myriad of sources:
- Emails and documents
- Images and videos
- Audio recordings
- Financial data
- Sensor data from IoT devices
- Text from websites and social media
The first step is to simply gather this information into one place.

Step 2: Data Cleaning
Raw data is messy. It’s full of errors, duplicates, and information that just doesn’t make sense. Before we can use it, we have to clean it up.
In this step, data scientists act as detectives, finding and fixing problems:
- Removing missing values: Like an empty cell in a spreadsheet.
- Deleting duplicates: So the AI doesn’t learn the same thing twice.
- Filtering out noise: Irrelevant data that might confuse the model.
- Handling outliers: These are data points that are wildly different from the rest. For example, if a dataset of human ages contains a “200-year-old human”, it’s clearly an error that needs to be removed.

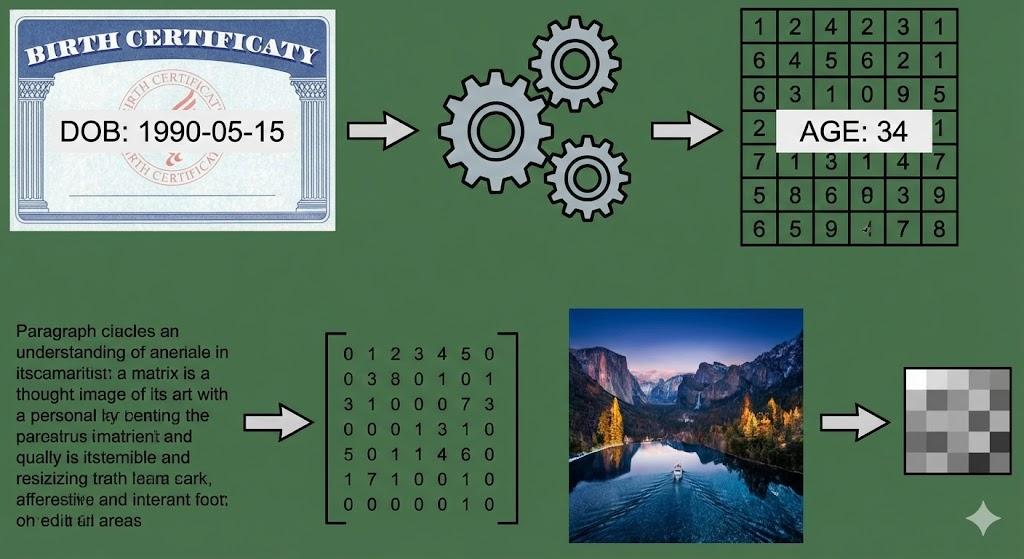
Step 3: Feature Engineering
Even clean data isn’t always in a format an AI can understand. Machines speak numbers, not text or dates. Feature engineering is the art of translating raw data into a language the AI can learn from (often done by a Data Scientist).
This involves creative transformations:
- Convert “Date of Birth” → Age: The model doesn’t care when you were born, it cares how old you are.
- Convert text → numerical vectors: Words are turned into long lists of numbers that represent their meaning.
- Resize images: All images are made the same size so the AI can compare them easily.
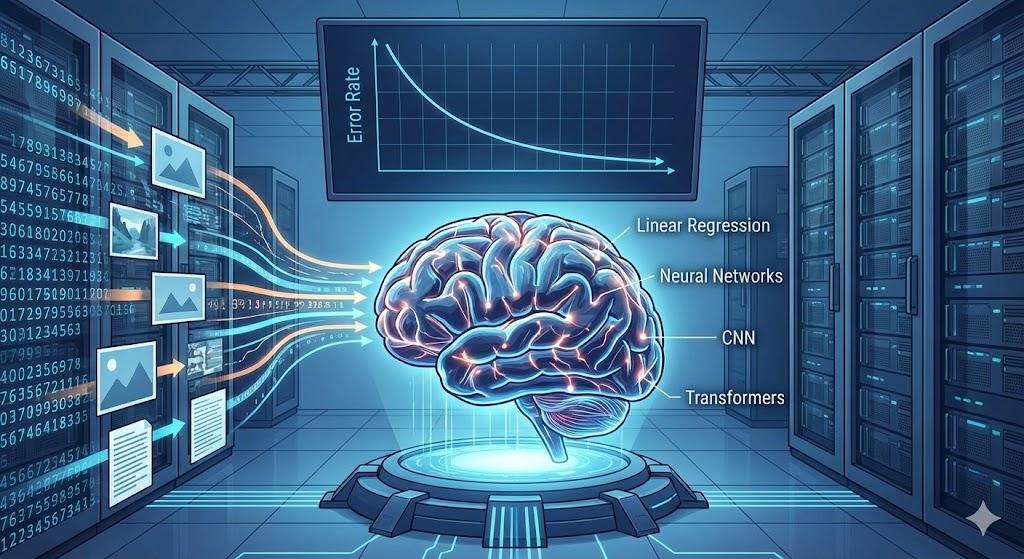
Step 4: Model Training
Now, the magic happens. We feed our prepared data into an algorithm. The goal of training is for the model to find mathematical patterns in the data. It’s a process of trial and error, repeated millions of times, until the model can make accurate predictions.
Different algorithms are used for different tasks:
- Linear Regression is great for finding simple trends (like predicting house prices - see Module 1.10).
- Neural Networks and CNNs (Convolutional Neural Networks) excel at learning complex patterns in images.
- Transformers are the state-of-the-art for understanding and generating human language.
Ultimately, training is a complex process of mathematical optimization, where the model tries to minimize the number of mistakes it makes.
Step 5: Model Evaluation
Before we let an AI out into the world, we need to know how good it is. We test the trained model on data it has never seen before.
We use various metrics to grade its performance:
- Accuracy: The overall percentage of correct predictions.
- Precision & Recall: These metrics are crucial when the cost of a mistake is high (e.g., in medical diagnosis).
- F1 Score: A balanced score that considers both precision and recall.
- ROC-AUC: A graph that shows how well the model can distinguish between different classes.
Step 6: Deployment
Once we are confident in our model’s performance, it’s time to make it accessible to users. This is called deployment.
An AI model can be deployed in many ways:
- As part of a web application or mobile app.
- As an API (Application Programming Interface) that other software can use.
- As a cloud function that runs on demand.
Step 7: Continuous Updating
The world is constantly changing, and an AI model that isn’t updated will quickly become obsolete. The final step is a continuous cycle of monitoring the model’s performance in the real world, collecting new data, and retraining it to improve its accuracy and adaptability over time.
What is the correct order of the AI Lifecycle?
Understanding this lifecycle is key to demystifying AI. It’s not magic; it’s a rigorous, iterative process of engineering, mathematics, and continuous learning.